
The Locale Explorer: Rich Edit with hyperlinks
|
|
Home |
 |
Back To Tips Page |
|
|
Back to LocaleExplorer |
|
|
The Locale Explorer: Rich Edit with hyperlinks |
|
The index became a serious effort. If had any idea that this project was going to become this complex, I used a combination of techniques that I had employed in other projects, and did this to develop a "toy help" system where the help is embedded in the executable. It turned out to not be a toy, and I'm not at all convinced it has scaled well. But I include it because it is worth illustrating a technique that can apply to modest projects.
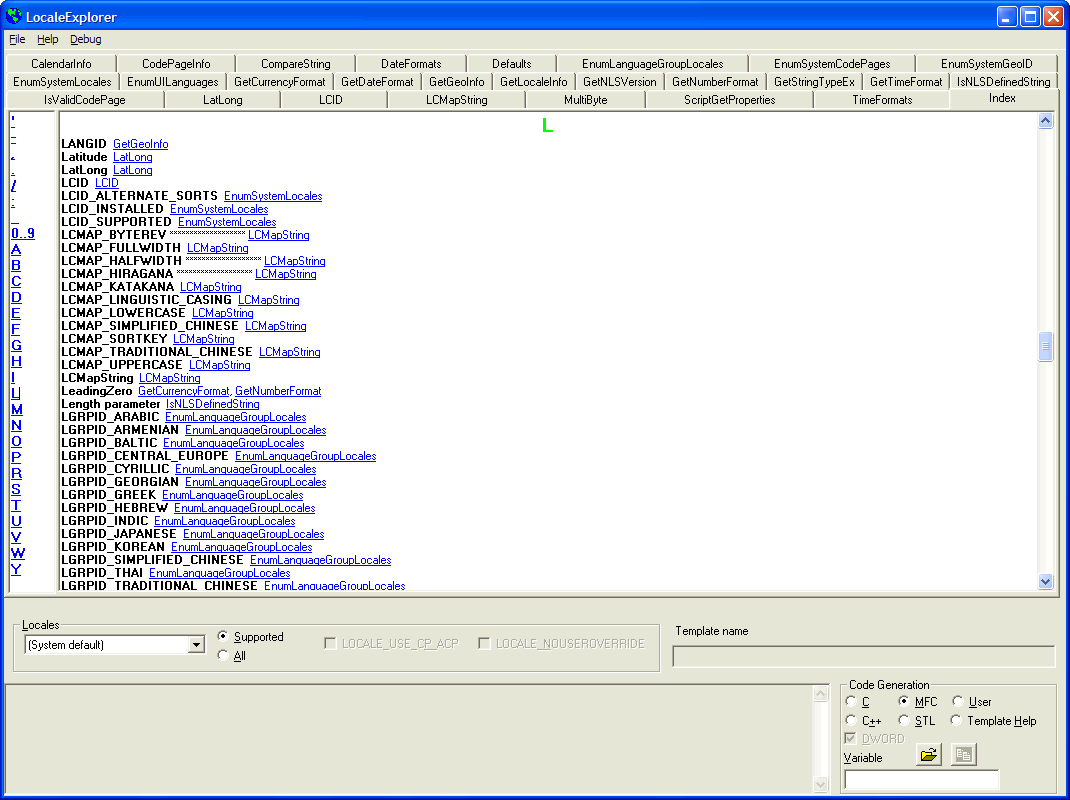
This index is created "on-the-fly". Each page contains a set of virtual methods that cause it to respond to indexing requests.
I added code to create the "quick index" on the left, which merely scrolls the right pane to the selected letter. The highlighted and underlined text represents a hyperlink which, when clicked, will move to the tab in which the keyword appears.
The key to this is the Rich Edit control. Unfortunately, Visual Studio supports some antiquated prototype of the Rich Edit control, and for reasons that are largely incomprehensible, even Visual Studio .NET 2003 only supports the primitive and obsolete Rich Edit 1.0 control. So some effort was required to make it all work.
First, I used the Resource Editor to install a Rich Edit control on the dialog, and selected the "Read-only" and "Multiline" styles. Then I went to my favorite text editor and hand-edited the localeexplorer.rc file. I modified the class name of the Rich Edit control to read
IDD_INDEX DIALOG DISCARDABLE 0, 0, 176, 90 STYLE WS_CHILD FONT 8, "MS Sans Serif" BEGIN CONTROL "",IDC_INDEX,"RICHEDIT20W",WS_BORDER | WS_VSCROLL | WS_TABSTOP | 0x804,33,0,142,90 CONTROL "",IDC_FASTINDEX,"RICHEDIT20W",WS_BORDER | WS_VSCROLL | WS_TABSTOP | 0x804,0,0,32,89 END
Note that the styles 0x0804 represent the style flags ES_READONLY (0x0800) and ES_MULTILINE (0x0001). The problem is that once I had read the resources in with the updated control type, the Resource Editor no longer recognized the symbolic translations and wrote the absolute hex value of the flags out.
This was just a small part of the solution. Next, I had to cause the Rich Edit control to properly initialize. In Visual Studio 6, I would have to call AfxInitRichEdit. In Visual Studio .NET 2003, I would have to call AfxInitRichEdit2. But this method does not exist in VS6. So what to do?
Well, I had already developed this facility to handle another project, my clock, so you can consult the documentation for that project. However, since my hyperlinks were not hyperlinks into the Internet, but into other pages in my application, I implemented the URL detection handler differently in this project.
I decided to index every control that had a caption. This was simple. I had the index iterate on every page of the tabbed dialog, and pick up its text. So if there was a radio button
¤ DATE_SHORTDATE
on the page "DateFormats", then I would create a reference to that page. In some cases, an API and its options appear on more than one page; in other cases, the options appear with more than one API (for example, CompareString and LCMapString), so there are multiple entries. However, after doing this, I found a lot of inappropriate controls were being indexed. So I added a virtual Boolean method to the class CFunction (from which all the pages are derived) which returns TRUE if the window should be indexed and FALSE if it should not be. The superclass always returns TRUE.
For example, one of the pages has the body
BOOL CDefaults::IndexOK(CWnd * wnd)
{
if(wnd == &c_GetUserGeoIDStatus)
return FALSE;
if(wnd == &c_GetUserDefaultUILanguageStatus)
return FALSE;
if(wnd == &c_GetUserDefaultLCIDStatus)
return FALSE;
if(wnd == &c_GetUserDefaultLangIDStatus)
return FALSE;
if(wnd == &c_GetSystemDefaultLangIDStatus)
return FALSE;
if(wnd == &c_ConvertDefaultLocaleStatus)
return FALSE;
return TRUE;
} // CDefaults::IndexOK
So each page gets to decide which of its windows should not be indexed.
The basic iteration loop is
void CFunction::Index()
{
for(ALL_CHILDREN(wnd))
{ /* children */
BOOL ok = FALSE;
ok |= IsButton(wnd);
ok |= IsStatic(wnd);
if(ok)
{ /* indexable control */
if(!IndexOK(wnd)) // page-specific filters: return FALSE to skip indexing
continue;
CString s;
wnd->GetWindowText(s);
if(s.IsEmpty())
continue;
TabParent->SendMessage(UWM_REFERENCE, (WPARAM)new Reference(s, this, wnd));
if(s[0] == _T('_'))
{ /* reindex */
CString prefix = s.SpanIncluding(_T("_"));
TabParent->SendMessage(UWM_REFERENCE, (WPARAM)new Reference(s, s.Mid(prefix.GetLength()), this, wnd));
} /* reindex */
} /* indexable control */
} /* children */
} // CFunction::Index
In order to avoid having to include the dialog class in every module, I use SendMessage to push the responsibility for whatever is to be done to the parent window. The actual code for the UWM_REFERENCE message is trivial:
LRESULT CLocaleExplorerDlg::OnReference(WPARAM wParam, LPARAM)
{
Reference * r = (Reference *)wParam;
References.Add(r);
return 0;
} // CLocaleExplorerDlg::OnReference
In addition, the caption of each page is added to the references as each page is added to the tabbed dialog.
Because the index takes a while to build, and I didn't always want to wait for it while debugging other pages, I added the -noindex option to the command line. In the main dialog, I added lines of code
BOOL noindex = FALSE;
...
for(int i = 0; i < __argc; i++)
{ /* see if noindex */
if(_tcsicmp(__targv[i], _T("-noindex")) ==0)
{ /* set noindex */
noindex = TRUE;
break;
} /* set noindex */
} /* see if noindex */
...
ADDPAGE(Unicode);
if(!noindex)
ADDPAGE(Index);
...
// Request the index be created
if(!noindex)
SendMessageToDescendants(UWM_INDEX, (WPARAM)&References, (LPARAM)progress);
This technique is a common way to send messages to some page, where you don't want to have to figure out which page is involved. A user-defined message that is only recognized by one page is simply sent to all descendants, and only the page that understands it responds. While some may argue that this is "inefficient", the cost of a single SendMessageToDescendants call at program startup is so completely irrelevant that even holding the discussion about efficiency illustrates a need to understand reality. Complexity matters. Performance matters only when it matters (see my essay on optimization).
As each link is added, it is marked as underlined, and in blue. The character range used to make this selection is stored in the hyperlink table. The References table entry is copied to the hyperlink table and forms the basis for performing the link; the enhancement to include the character range allows detecting if the mouse hit is within a particular hyperlink.
Notification messages about a click on a hyperlink are sent via a WM_NOTIFY message with the notification code EN_LINK. This is not supported by ClassWizard, so the notification has to be added by hand:
ON_NOTIFY(EN_LINK, IDC_INDEX, OnLinkIndex)
The function, of course, must also be added manually, and looks like the sketch below. Note that notifications will come in for a variety of notifications, including WM_MOUSEMOVE, so a specific check is made to see if the event is a button click. The character-range of the hyperlink is given in the chrg member of the ENLINK structure, and the IsMatch method I wrote just checks the hyperlink table for the match.
void CIndex::OnLinkIndex(NMHDR* pNMHDR, LRESULT* pResult)
{
ENLINK * event = (ENLINK *)pNMHDR;
if(event->msg == WM_LBUTTONDOWN)
{ /* do hyperlink */
for(int i = 0; i < hyperlinks.GetSize(); i++)
{ /* scan links */
if(hyperlinks[i]->IsMatch(event->chrg))
{ /* hit it */
CTabView * parent = (CTabView *)hyperlinks[i]->page->GetParent();
parent->ActivatePage(hyperlinks[i]->index);
break;
} /* hit it */
} /* scan links */
} /* do hyperlink */
*pResult = 0;
}
To enable link detection, the Rich Edit control must have its notification capability enabled. I chose to set this in the PreSubclassWindow handler for the class which implements the rich edit subclass:
void CIndexText::PreSubclassWindow()
{
SetEventMask(ENM_LINK);
} // CIndexText::PreSubclassWIndow
Having developed what turned into an extensive index, I found it inconvenient to have to scroll it down to an area I wanted to examine. So using the same technology that I used for the main window, I added a "Fast Index", which holds just the initial letters (or in some cases, a representative letter). During construction, I created another array, the fastindex array, that holds references to the starting entry for each letter. I then created a different handler. This uses the same technique for matching, but the action is to compute the line on which the element appears. There is no way to do something useful, such as SetFirstVisibleLine (another gross omission from the Rich Edit Control), but I could compute the amount necessary to scroll, given the current visible line (obtained from GetFirstVisibleLine), and use LineScroll to scroll the control.
ON_NOTIFY(EN_LINK, IDC_FASTINDEX, OnLinkFastIndex)
void CIndex::OnLinkFastIndex(NMHDR* pNMHDR, LRESULT* pResult)
{
ENLINK * event = (ENLINK *)pNMHDR;
if(event->msg == WM_LBUTTONDOWN)
{ /* do hyperlink */
for(int i = 0; i < fastlinks.GetSize(); i++)
{ /* scan links */
if(fastlinks[i].IsMatch(event->chrg))
{ /* hit it */
CHARRANGE r = fastlinks[i].chrg;
c_Index.SetSel(r);
int pos = fastlinks[i].selection.cpMin;
long line = c_Index.LineFromChar(pos);
int visible = c_Index.GetFirstVisibleLine();
// Scroll until line is visible
// We have the following cases
// line < visible
// Scroll towards beginning until current line is visible
// LineScroll(line - visible);
// line = visible
// do nothing
// line > visible
// Scroll towards end until current line is visible
// LineScroll(line - visible);
c_Index.LineScroll(line - visible);
break;
} /* hit it */
} /* scan links */
} /* do hyperlink */
*pResult = 0;
} // CIndex::OnLinkFastIndex
The problem was that indexing took a noticeable amount of time on each startup. Eventually, I decided that this was just not acceptable. What I had to do was cache the index. This involved serializing the data to a file. This should be done only once; after that, the validity of the cache can be checked, and if it is invalid, it can be recomputed, otherwise the data is retrieved from the cache. But this is not as easy as it looks. The cache contains hyperlink information, but this information, as already described, is kept in auxiliary tables. So while I could fairly readily write out the RTF data, when read back in, all I had was pretty text. No actual "active" text. RTF files have no way to remember the CFE_LINK state of the characters.
I could have used archive files to hold this, but I have never quite trusted the archive mechanism. This is because the archive mechanism is fairly sensitive to schema evolution. In the case of this application, I could have gotten away with it, because there is essentially no schema evolution. The data layout is unique to each compilation of the program, and therefore there is no need to maintain backward-compatibility of legacy data. However, I chose to ignore it anyway.
There are several mechanisms that can be used in place of CArchive.
Binary files are sensitive to schema evolution, but that is not an issue which this program needs to address. I actually chose this representation, although it has limited flexibility. It has the advantage that it is usually easy to implement. The downside is that it is hard to maintain. But given how few items I need to write, this is not an issue.
Tagged binary files are much more flexible. For decades they were my implementation of choice. A tagged binary file is essentially binary XML. Each block of data consists of a tag value, a numeric value, and a length. Within each block, each value has a tag and a length. If you are reading an older file, you can just read the tag and length; if the block type is obsolete, add the length to the start of the block and read the next block. Many years ago, in a system called LG (a precursor of XML, designed to specs I first wrote in 1977), we actually kept the "unknown binary data" and could write it back out when the data structure was rewritten. This tool supported research, and later, production, compiler development for many years. It was also the precursor of a system called IDL, which was the next generation.
Text files are pretty obvious, and are merely an implementation of binary files where the contents are represented as text. Line-delimited, tab-delimited, and comma-delimited text all represent text files.
Tagged text files are text files that impose a structure. The ultimate development of tagged text files these days is XML. XML is a particular syntax for a tagged text file.
My mechanism of choice these days is XML, but this would involve incorporating an XML library into my code (I would never consider DOM format or the libraries that support it; these were designed by amateurs and do not support realistic data structures. For example, in DOM each child node contains a pointer back to its parent. There is no provision for the creation of directed acyclic graphs or cyclic graphs, where a child can have several parents. Realistic structures; those not constrained by the foolish restrictions of DOM, are far more important, and therefore DOM is pointless for realistic data structure descriptions).
In any cache situation, cache invalidation is an important part of the mechanism. We have to know when the cached information is invalidated, so new information can be recreated. For this system, I chose to write a timestamp in the front of the cache file, where the timestamp is the timestamp of the executable file. So when a new executable is built, by definition it makes the old cache obsolete.
The structure of the file is shown below
| Offset | Data type | Description |
| 0 | FILETIME time | Creation timestamp of the executable image that created this index |
| sizeof(FLETIME) | DWORD eod1 | Offset to start of next block of data |
| sizeof(FILETIME)+sizeof(DWORD) | BYTE | RTF data produced by StreamOut: index contents |
| eod1 | DWORD hypercount; | Count of hyperlinks for index entries |
| eod1 + sizeof(DWORD) | LinkItem[] | array of link items |
| eod1 + hypercount * sizeof(LinkItem) | DWORD eod2 | Offset to start of next block of text |
| eod1 + hyperount * sizeof(LinkItem) + sizeof(DWORD) | BYTE | RTF data produced by StreamOut: fast-index contents |
| eod2 | DWORD fastcount | Count of fast-index entries as hyperlinks |
| eod2 + sizeof(DWORD) | LinkItem[] | array of link items for fastlink entries |
At the beginning I write a FILETIME time which represents the timestamp of the executable image that wrote it. Normally, the first element of a file is the "file version number" that tells how to interpret the contents of the file. For the cache file, the "file version number" is simply the timestamp, because if the executable file changes, the presumption is that the cache is no longer valid. So the "file version number" in the file does not match the version number of the executable, and consequently the cache contents are irrelevant and can be rewritten. Note that now schema evolution is no longer a problem: if I decide to change the representation of the cache, I have to generate a new executable, and of course this means the old contents, besides being in the wrong format, are irrelevant and will be rewritten.
This is followed by two similar blocks of code. The first block is the RTF text and hyperlink data for the right panel, which is the index itself. The second block is the RTF text and hyperlink data for the left panel, which is the "fast index" into the index itself.
Obviously, a file needs to be written somewhere. Where should this be? I chose the default to be in the same directory as the executable. If the user wishes to redirect it, the path can be stored as a Registry key. Using my Registry class, I simply read the key to see if there is a value.
BOOL CIndex::GetCacheFile(CString & name)
{
RegistryString path(IDS_REGISTRY_CACHE_PATH);
BOOL found = path.load();
if(!found || path.value.IsEmpty())
{ /* use default path */
TCHAR exepath[MAX_PATH];
if(!::GetModuleFileName(NULL, exepath, MAX_PATH))
return FALSE;
TCHAR drive[MAX_PATH];
TCHAR dir[MAX_PATH];
_tsplitpath(exepath, drive, dir, NULL, NULL);
_tmakepath(exepath, drive, dir, _T("index"), _T(".dat"));
name = exepath;
} /* use default path */
else
{ /* use specified path */
path.value.TrimRight();
if(path.value.Right(1) != _T("\\"))
path.value += _T("\\");
path.value += _T("index.dat");
name = path.value;
} /* use specified path */
The cache path value is set from a menu item.
void CLocaleExplorerDlg::OnCacheLocation()
{
RegistryString path(IDS_REGISTRY_CACHE_PATH);
path.load();
BROWSEINFO info = {0};
info.hwndOwner = m_hWnd;
info.pidlRoot = NULL;
info.pszDisplayName = path.value.GetBuffer(MAX_PATH);
info.ulFlags = BIF_EDITBOX | BIF_NEWDIALOGSTYLE);
LPITEMIDLIST list = SHBrowseForFolder(&info);
if(list == NULL)
return;
path.value.ReleaseBuffer();
SHGetPathFromIDList(list, path.value.GetBuffer(MAX_PATH));
path.value.ReleaseBuffer();
path.store();
}
The code to write this file uses the StreamOut method of CRichEditCtrl. Note that the "cookie" is somewhat more sophisticated than the toy example in the MSDN, and note also that the horrid error where the cookie is listed as a DWORD, and cast as a DWORD, has been fixed. The dwCookie field is actually a DWORD_PTR, which once again illustrates why Hungarian Notation should never be used. It is said to be a dw, but following the rules it should actually be declared a dwp. This notation was erroneously adopted by the Windows group (the correct usage is logical type, not implementation type!), and has led to nothing but complete confusion because of the numerous errors in its usage (a quick perusal of the header files will reveal wonderful blunders where the notation indicates one type and the declaration is another, unrelated type!).
The StreamOut function requires a CALLBACK function. The EDITSTREAM structure carries two values to configure this. One is the "cookie" to be passed to the callback function, the other value is the pointer to the callback function itself.
EDITSTREAM es;
es.dwCookie = (DWORD_PTR)&OutStream;
es.pfnCallback = StreamOutCallback;
Where an OutStream variable is defined as a type StreamOutCookie
class StreamOutCookie {
public:
CFile * file;
DWORD LengthOffset;
DWORD err;
};
The CFile * is obvious: it will indicate the target of the bytes being written. Each time I write some bytes to the RTF stream, I update the actual length. I chose to set this to be a pointer to the start of the next object in the file, for reasons that seemed sensible at the time and may or may not be, but it represents a choice (this is an example of a "bridge-color problem", wherein I have to bind decisions because if they are unbound, I can't proceed. But the bindings are arbitrary and can be whatever I want them to be). The LengthOffset is the offset, in bytes, in the file, where I have written the length word. Initially, I write a length word of 0.
To write out the hypertext, the code is
StreamOutCookie OutStream;
OutStream.file = &output;
OutStream.LengthOffset = output.GetPosition();
OutStream.err = 0;
//****************************************************************
// [eod ] Offset of end-of-data for RTF data
//****************************************************************
DWORD zero = 0; // start out with 0 length
output.Write(&zero, sizeof(DWORD));
EDITSTREAM es;
es.dwCookie = (DWORD_PTR)&OutStream;
es.pfnCallback = StreamOutCallback;
//****************************************************************
// <...> RTF data
//****************************************************************
c_Index.StreamOut(SF_RTF, es)
if(OutStream.err != ERROR_SUCCESS)
{ /* get out */
output.Close();
return;
} /* get out */;
I had two choices in how to respond to errors on output; one was to let the callback throw an exception, but I wasn't sure what the implications would be on the rich text control if an exception were thrown. Instead, I chose to set an error value in the StreamOutCookie structure which I could test. Admittedly, in the C++ framework this method is a bit retro, but lacking a well-defined behavior of the streaming mechanism, I chose conservatively.
The StreamOutCallback function is
/* static */ DWORD CALLBACK CIndex::StreamOutCallback(DWORD_PTR cookie, LPBYTE buffer, LONG count, LONG * pcb)
{
StreamOutCookie * StreamOut = (StreamOutCookie *)cookie;
StreamOut->file->Write(buffer, count);
DWORD pos = StreamOut->file->GetPosition(); // get current position (files are all < 4.2GB)
StreamOut->file->Seek(StreamOut->LengthOffset, CFile::begin); // go back to length word
try {
StreamOut->file->Write(&pos, sizeof(DWORD));
}
catch(CFileException * e)
{ /* failed */
StreamOut->err = e->lOsError;
*pcb = 0;
e->Delete();
return 1;
} /* failed */
StreamOut->file->SeekToEnd(); // reposition at end
*pcb = count;
StreamOut->err = ERROR_SUCCESS;
return 0;
} // CIndex::StreamOutCallback
Next, I needed to write out the hyperlink information so that when the mouse traversed a hyperlink the appropriate cursor action would take place, and when clicked it would select the correct page.
The approach here illustrates some of the need for rapid prototyping as an approach, contrasted to the traditional "waterfall" model. In the "waterfall model", all design would be done before coding began, and all decisions about data structures would be highly codified. However, the "fast index" on the left was added because I discovered that, after trying to use the program, that an additional specification, initially unanticipated, would be required. So I coded up a second table to provide the fast index. But when it came time to write out the cache data, I realized these two tables had a lot in common. So I added a superclass to capture that commonality:
class LinkItem {
public: // Construction/initialization
LinkItem() { Clear(); }
LinkItem(CHARRANGE & c1, int n) { range = c1; index = n; }
void Clear() { range.cpMin = range.cpMax = index = 0; }
public: // Testing
BOOL IsMatch(CHARRANGE & r) { return r.cpMin == range.cpMin; }
public: // I/O
BOOL Read(CFile & file);
BOOL Write(CFile & file);
public:
//================================================================+
// These are the variables serialized when the hyperlink is |
// written out to the index cache |
//================================================================+
CHARRANGE range; // |
int index; // page index // |
//================================================================+
};
Now all of my link reading and writing was encapsulated in one class, which provided the serialization. I could have chosen to designate the Read and Write functions as "Serialize", but that would lead to confusion because someone might think that I was using MFC serialization. Also, I believe that if reading and writing are separate, lumping the two of them together into a single function that has to test to see if it is doing input or output is downright silly. Separate them!
From this class I derived two subclasses, one of which is quite trivial.
class FastIndexItem : public LinkItem {
public:
FastIndexItem(CHARRANGE & c1, CHARRANGE & c2) : LinkItem(c1, c2.cpMin) { } //{ chrg = c1; selection = c2; }
FastIndexItem() : LinkItem() { }
};
//===========================================================================
class Reference : public LinkItem {
public:
Reference(CString s, CFunction * p, CWnd * w);
Reference(CString s, CString s_as, CFunction * p, CWnd * w);
Reference() : LinkItem() { }
static void Canonicalize(CString & s);
public:
//================================================================+
// These are used to construct the index, but are not needed |
// after construction, so they do not need to be saved in the |
// cache |
//================================================================+
CFunction * page; // |
CWnd * wnd; // |
CString text; // |
CString textAs; // |
//================================================================+
protected:
void Set(const CString & s, const CString & as, CFunction * p, CWnd * w);
};
In the second class, Reference, I need to create a lot of information to allow me to sort the index information. But as the comment indicates, once the index has been created, there is no need for any of this information to use the index, so it does not need to be saved. Only the LinkItem components need to be saved.
This commonality might have been missed in a traditional waterfall design, but was evident once the need to do caching was determined.
Writing the link data out was straightforward:
//****************************************************************
// [count ] count of hyperlinks
//****************************************************************
DWORD len = hyperlinks.GetSize();
output.Write(&len, sizeof(len));
//****************************************************************
// <...> hyperlink data
//****************************************************************
for(int i = 0; i < hyperlinks.GetSize(); i++)
{ /* write each hyperlink */
hyperlinks[i]->Write(output);
} /* write each hyperlink */
The writing of the fastlink data exactly parallels this and is not given here.
To simplify error recovery, I did not write out the timestamp at the beginning, but instead wrote out a dummy timestamp. This way, if I closed the cache due to an I/O error, it would be recognized as an invalid cache. At the end, as the last operation, I did a SeekToBegin and wrote the valid timestamp.
TimeStamp t;
if(!GetExeTimeStamp(t))
{ /* failed */
output.Close();
return;
} /* failed */
output.SeekToBegin(); // overwrite dummy timestamp with valid one
output.Write(&t, sizeof(t));
Reading the cache is fairly easy. The StreamIn method of the Rich Edit control is used in a manner somewhat symmetric with the StreamOut method. The cookie is different
class StreamInCookie {
public:
CFile * file;
DWORD remaining;
DWORD err;
};
Instead of an offset into the file, which was used for updating the position for output, I put a byte count of the number of bytes remaining to be read. This is initailized as
StreamInCookie streamIn; //
streamIn.file = &f;
//****************************************************************
// [Timestamp]
//****************************************************************
TimeStamp ft;
if(f.Read(&ft, sizeof(TimeStamp)) == 0)
{ /* failed */
ResetAllContent();
f.Close();
return FALSE;
} /* failed */
//****************************************************************
// [eod] End of data position for RTF data
//****************************************************************
if(f.Read(&streamIn.remaining, sizeof(DWORD)) == 0)
{ /* failed */
ResetAllContent();
f.Close();
return FALSE;
} /* failed */
// Now convert from offset to length
streamIn.remaining -= f.GetPosition();
//****************************************************************
// <...> RTF data
//****************************************************************
EDITSTREAM es;
es.dwCookie = (DWORD_PTR)&streamIn;
es.pfnCallback = StreamInCallback;
c_Index.StreamIn(SF_RTF, es);
if(streamIn.err != ERROR_SUCCESS)
{ /* failed */
f.Close();
ResetAllContent();
return FALSE;
} /* failed */
The timestamp is read and discarded (it has been separately checked for validity, and therefore is no longer needed). The end-of-data pointer is read, and converted to a length by subtracting the offset of the current file position (the start of the RTF data) from the end-of-data value. This is then used by the StreamIn callback function to determine how much data to read, and is adjusted appropriately.
The ResetAllContent function clears any partial state that may have been created, so that subsequent operations will not inherit partial data.
The callback method for input is
/* static */ DWORD CALLBACK CIndex::StreamInCallback(DWORD_PTR cookie, LPBYTE buffer, LONG count, LONG * pcb)
{
StreamInCookie * streamIn = (StreamInCookie *)cookie;
if(streamIn->remaining == 0)
{ /* all done */
*pcb = 0;
streamIn->err = ERROR_SUCCESS;
return 1; // nonzero value terminates read
} /* all done */
DWORD bytesToRead = min(streamIn->remaining, (DWORD)count);
UINT bytesRead;
try {
bytesRead = streamIn->file->Read(buffer, bytesToRead);
}
catch(CFileException * e)
{ /* catch */
streamIn->err = e->lOserror;
e->Delete();
streamIn->remaining = 0;
return 1;
} /* catch */
if(bytesRead == 0)
{ /* read error */
streamIn->err = ::GetLastError();
*pcb = bytesRead;
return 1; // return nonzero to stop operation
} /* read error */
streamIn->remaining -= bytesRead;
*pcb = bytesRead;
streamIn->err = ERROR_SUCCESS;
return 0;
} // CIndex::StreamInCallback
The count parameter tells how long the buffer is. We cannot read more than count bytes, but the number of bytes in the text might exceed this. Therefore, we read the min(count, remaining) bytes. Note that Microsoft is again exhibiting their confusion about lengths. Sometimes lengths are given as DWORDs and sometimes as UINTs, and all too often as LONG or int, as if the concept of a negative length makes sense (much of this is inherited from the original K&R C, where there was no unsigned data type).
Reading the hyperlinks is only part of the problem. The RTF text does not encode the hyperlink (the CFM_LINK property is not retained). So the hyperlink property has to be added back. Since this has to take place on both the main index page and the left-hand fast index panel, a common function handles it
void CIndex::MarkLink(CRichEditCtrlEx & ctl, CHARRANGE & range)
{
CHARFORMAT2 linkfmt;
ctl.SetSel(range);
linkfmt.cbSize = sizeof(CHARFORMAT2);
linkfmt.dwMask = CFM_LINK;
//c_Index.GetSelectionCharFormat(linkfmt);
linkfmt.dwEffects = CFE_LINK;
linkfmt.dwMask = CFM_LINK;
ctl.SetSelectionCharFormat(linkfmt);
} // CIndex::MarkLink
This is then called by a simple loop, the loop that reads the hyperlinks in. There is one loop for each of the controls
for(DWORD i = 0; i < len; i++)
{ /* read each */
hyperlinks[i] = new Reference;
if(!hyperlinks[i]->Read(f))
{ /* failed */
if(::GetLastError() == ERROR_HANDLE_EOF)
break; // "failure" is EOF (see spec on Reference::Read)
f.Close();
ResetAllContent();
return FALSE;
} /* failed */
MarkLink(c_Index, hyperlinks[i]->range);
} /* read each */
...
for(i = 0; i < len; i++)
{ /* read each */
if(!fastlinks[i].Read(f))
{ /* failed */
if(::GetLastError() == ERROR_HANDLE_EOF)
break;
f.Close();
ResetAllContent();
return FALSE;
} /* failed */
MarkLink(c_FastIndex, fastlinks[i].range);
} /* read each */
A FILETIME is a pair of DWORDs. Like many 64-bit types in Windows, instead of using a native 64-bit data type, we have a pair of DWORDs representing a value. Why this foolishness? The story goes that when the Windows group went to the compiler group and asked for a 64-bit data type, the compiler group couldn't be bothered. This short-sighted decision has cost us a lot over the years. I am tired of dealing with such childishness, and have endeavored to remove all traces of DWORD pairs from my code, whenever possible.
class TimeStamp : public FILETIME{
public:
// Construction
TimeStamp() { dwLowDateTime = dwHighDateTime = 0; }
TimeStamp(HANDLE h) { SetFileTime(h); }
TimeStamp(CFile & f) { SetFileTime(f); }
TimeStamp(LPCTSTR s) { WIN32_FIND_DATA fd;
HANDLE h = ::FindFirstFile(s, &fd);
if(h == INVALID_HANDLE_VALUE)
{ dwLowDateTime = dwHighDateTime = 0; }
else
{
*this = fd.ftCreationTime;;
::FindClose(h);
}
}
TimeStamp(FILETIME t) { SetFileTime(t); }
public: // Comparison operators
BOOL operator ==(TimeStamp & t) { return GetTime() == t.GetTime(); }
BOOL operator !=(TimeStamp & t) { return GetTime() != t.GetTime(); }
BOOL operator < (TimeStamp & t) { return GetTime() < t.GetTime(); }
BOOL operator <=(TimeStamp & t) { return GetTime() <= t.GetTime(); }
BOOL operator >=(TimeStamp & t) { return GetTime() >= t.GetTime(); }
BOOL operator > (TimeStamp & t) { return GetTime() > t.GetTime(); }
public:
LONGLONG GetTime() { LARGE_INTEGER t; t.LowPart = dwLowDateTime; t.HighPart = dwHighDateTime; return t.QuadPart; }
public:
BOOL SetFileTime(CFile & f) { return ::GetFileTime((HANDLE)(HFILE)f, this, NULL, NULL); }
BOOL SetFileTime(HANDLE h) { return ::GetFileTime(h, this, NULL, NULL); }
void SetFileTime(FILETIME t) { *(FILETIME *)this = t; }
};
There are some caveats when doing this, such as the limitation that the new class derived from a C struct, cannot be allowed to have virtual members, even virtual destructors.
Note the collection of constructors. The default constructor simply creates a zeroed timestamp. Other constructors work on various representations of files (since TimeStamp is a subclass of FILETIME, it seemed reasonable to have a set of constructors based on file objects). Finally, there is a constructor that initializes a TimeStamp object from a FILETIME value.
The GetTime method creates a 64-bit integer representing the time. Using this method, I was able to define a set of comparison operators.
For the index, to improve performance, I use caching. I don't have to recompute the entire index each time the program starts. just when the program has changed (a chance could be a change that added, deleted, or renamed an indexable entity). In the case of the Unicode display, the computations were lengthy. It is also worth reading my essay on optimization. Optimization does not matter until it matters. But once it matters, it matters a lot, and optimizing lines of code rarely is the correct approach to the problem. I've spent about 15 years of my life involved in performance measurement, and one thing I learned was that only inner loops matter when it comes to optimizing lines of code. Other performance is gained at the architectural level. Working on making the indexing code faster might have gained 10%. With a lot of work tuning the code, I might have gotten 15% improvement. But with less work, but by using major architectural changes, I got improvements of orders of magnitude. That is where to put effort.
You may notice in the above listing that some elements have a string "*******************" in front of them. This only appears in the Debug version. These elements represent windows that would have online help describing them, but the online help has not been written. I saw no reason I should have to figure out which elements did not have help by trying to correlate controls to resources, or try to figure out which ones didn't work. Instead, when it comes time to add a key, I also check to see if it is a help-capable control, and try to locate the online help text for it. If this fails, I put out the string of asterisks. As time and interest permitted, I would then create the missing help text.
![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.